t-SNE
t-distributed Stochastic Neighbor Embedding


by Kemal Erdem | @burnpiro
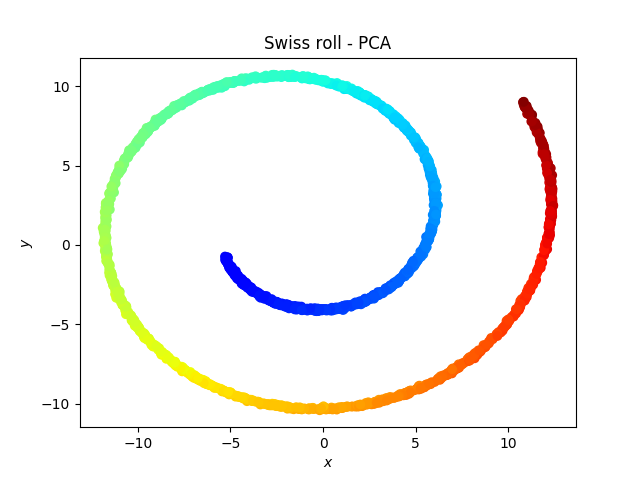
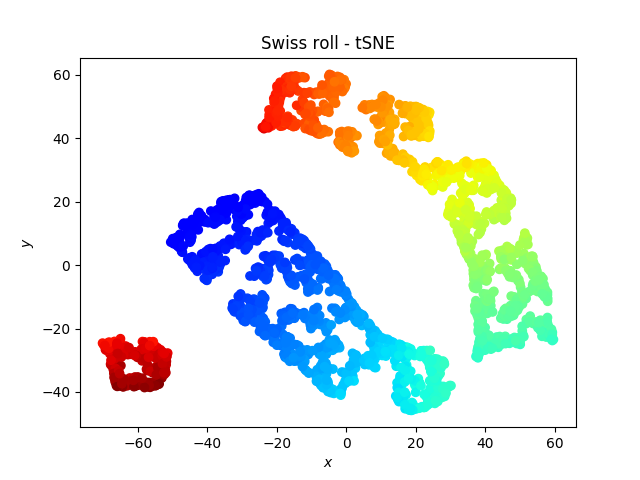
What is t-SNE?
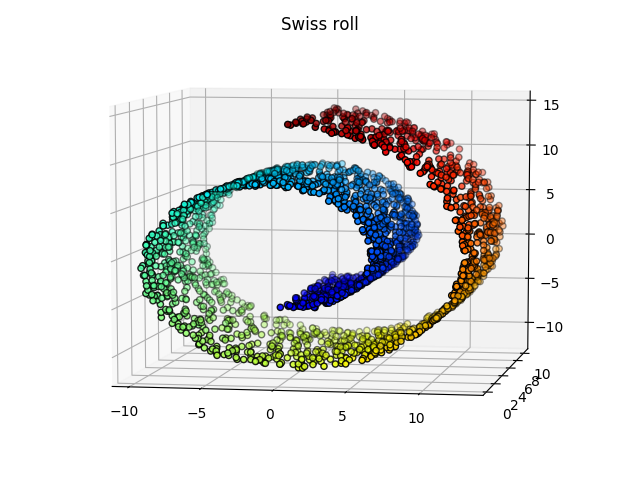 t-SNE vs PCA
https://mademistakes.com © Michael Rose
t-SNE vs PCA
https://mademistakes.com © Michael Rose
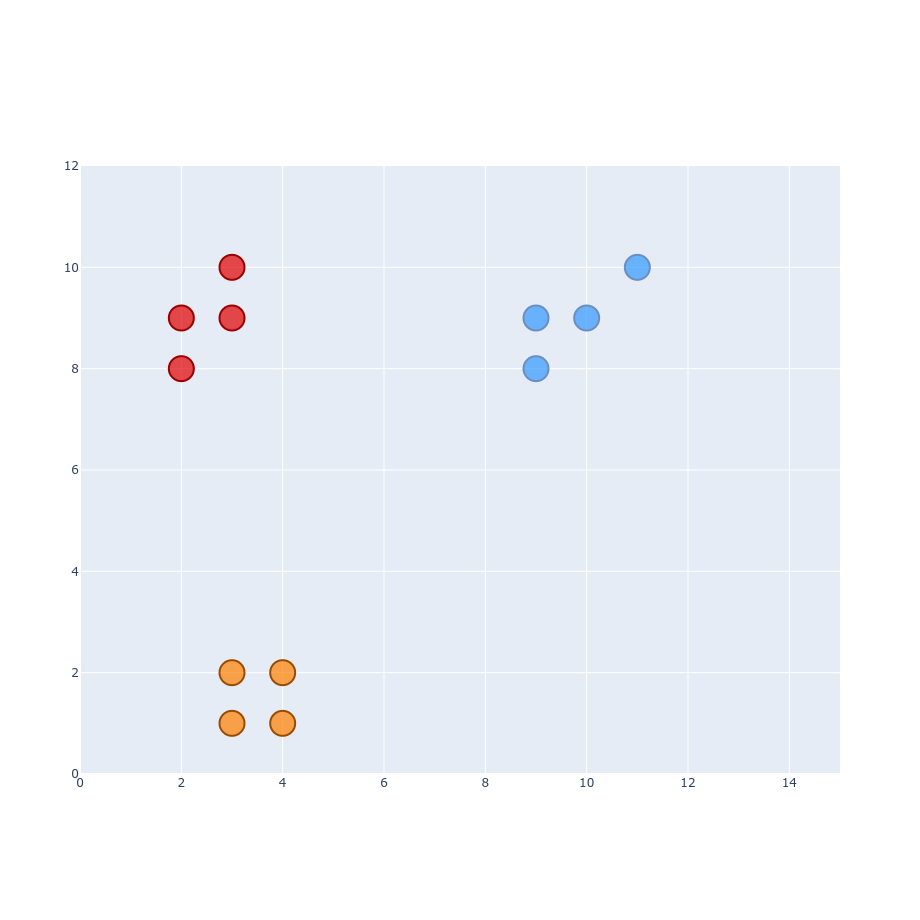
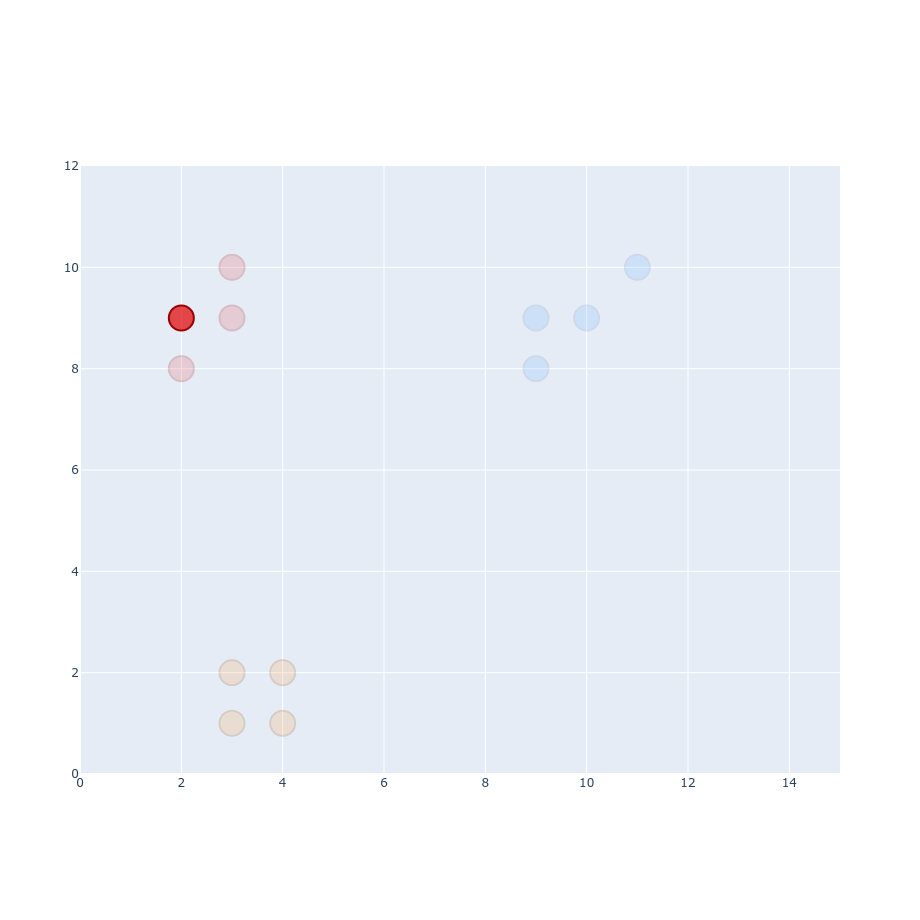
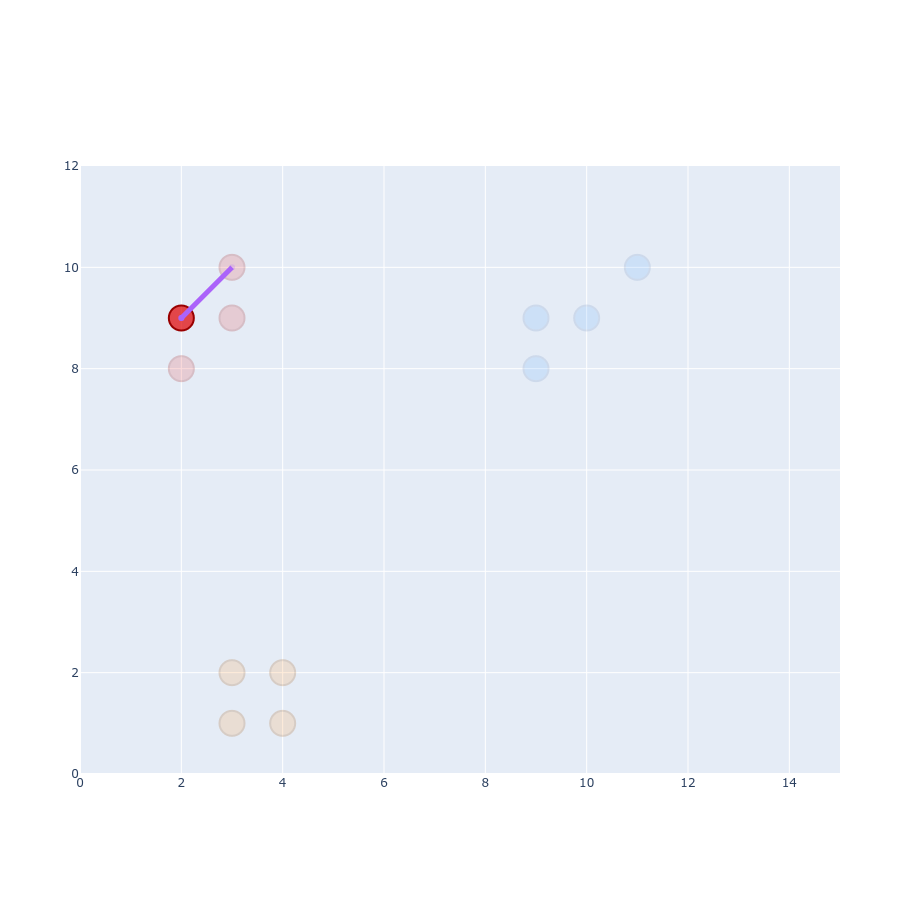
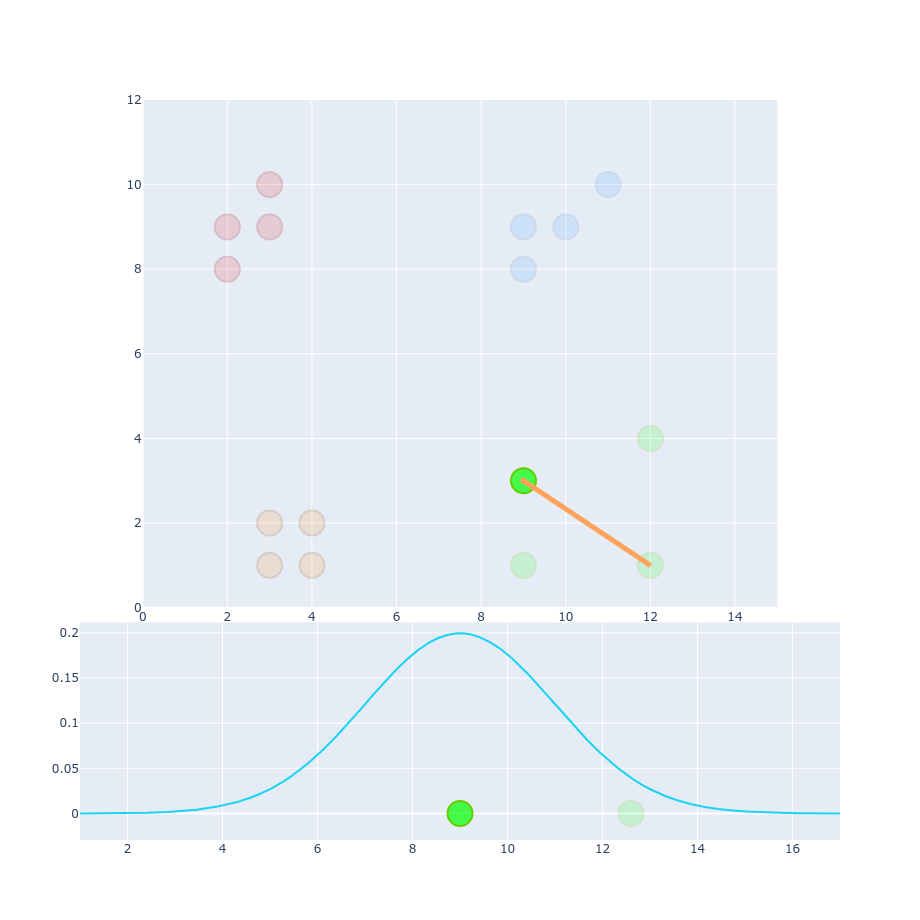
$$ p_{j|i} = \frac{g(| x_i - x_j|)}{\sum_{k \neq i}g(|x_i - x_k|)} $$ $$ p_{j|i} = \frac{0.177}{0.177 + 0.177 + 0.164 + 0.0014 + 0.0013 + ...} \approx 0.34 $$ $$ p_{j|i} = \frac{0.077}{0.077 + 0.064 + 0.064 + 0.032 + 0.031 + ...} \approx 0.27 $$
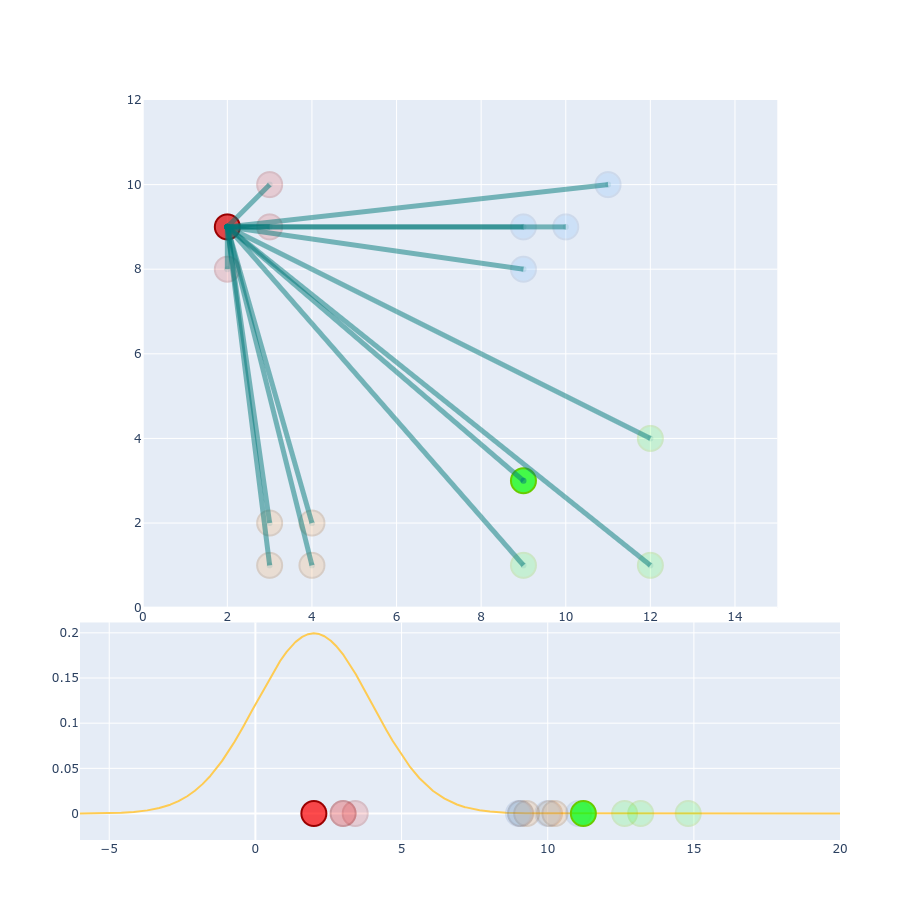
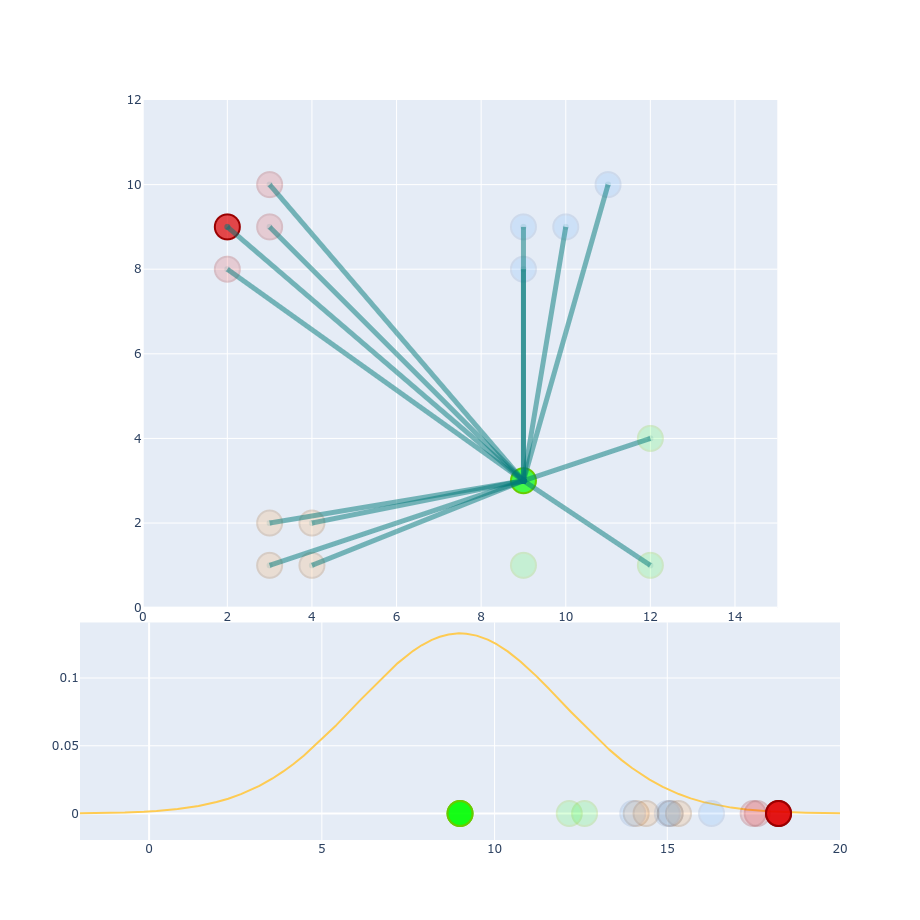
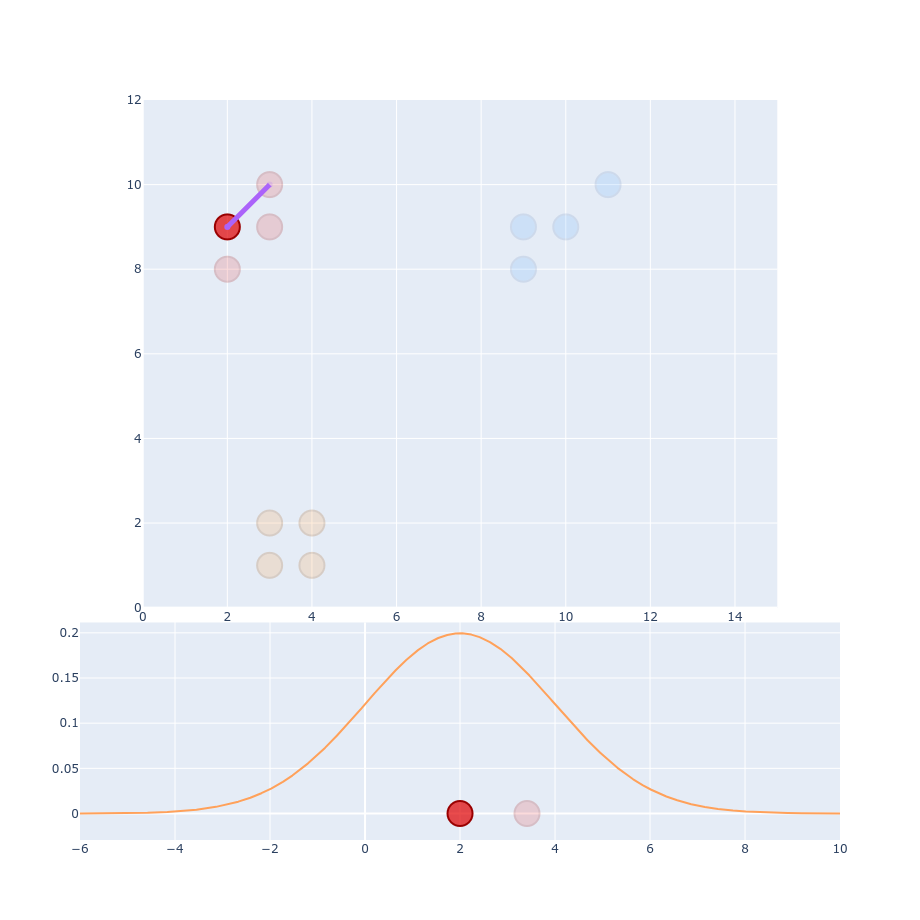
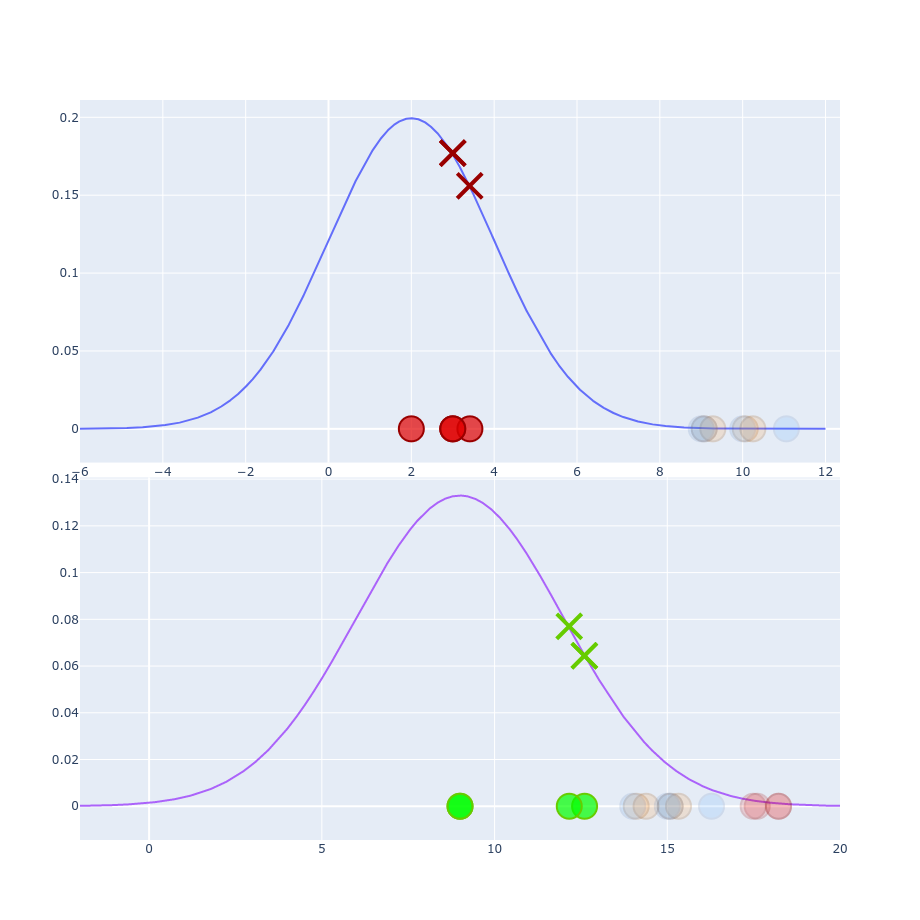
$$ Perp(P_i) = 2^{-\sum p_{j|i}\log_2 p_{j|i} } $$ Perp - target number of neighbors
$$ p_{j|i} = \frac{g(| x_i - x_j|)}{\sum_{k \neq i}g(|x_i - x_k|)} $$ $$ p_{j|i} = \frac{\exp(-\left | x_i - x_j \right |^2 / 2\sigma_i^2)}{\sum_{k \neq i} \exp(- \left | x_i - x_k \right |^2 / 2\sigma_i^2)} $$ $$ \frac{1}{\sigma \sqrt{2\pi}} \exp(-\frac{1}{2} \left ( \frac{x_i - x_j}{\sigma} \right ) ^2) $$
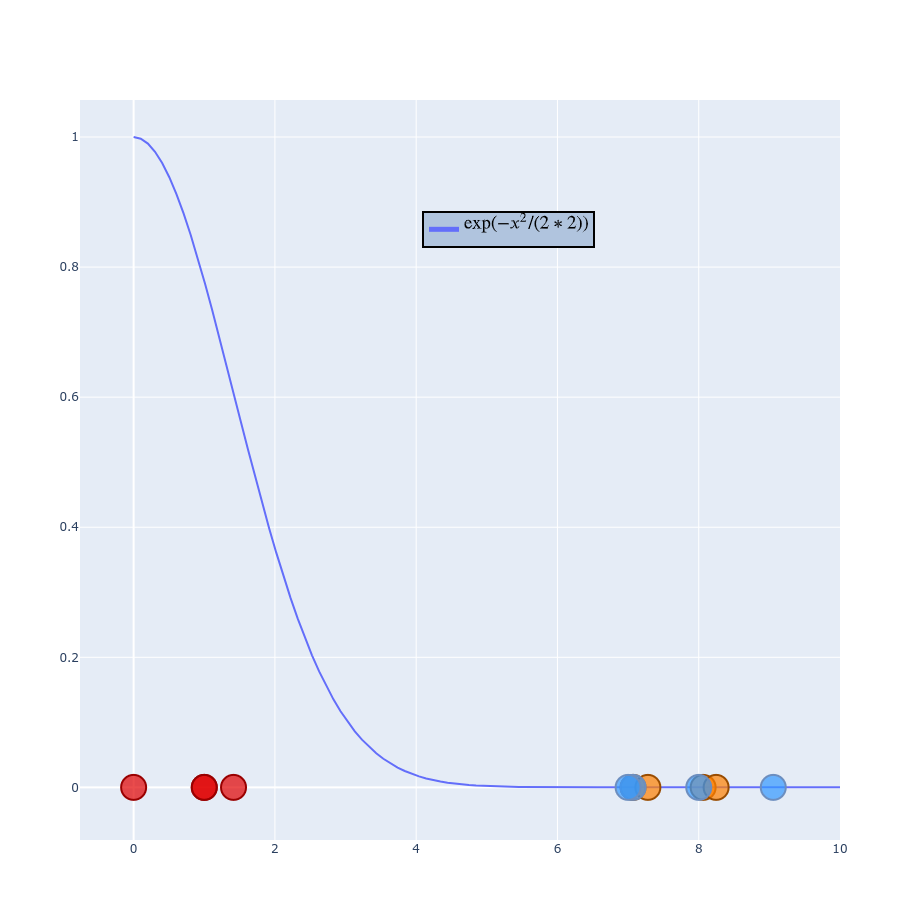
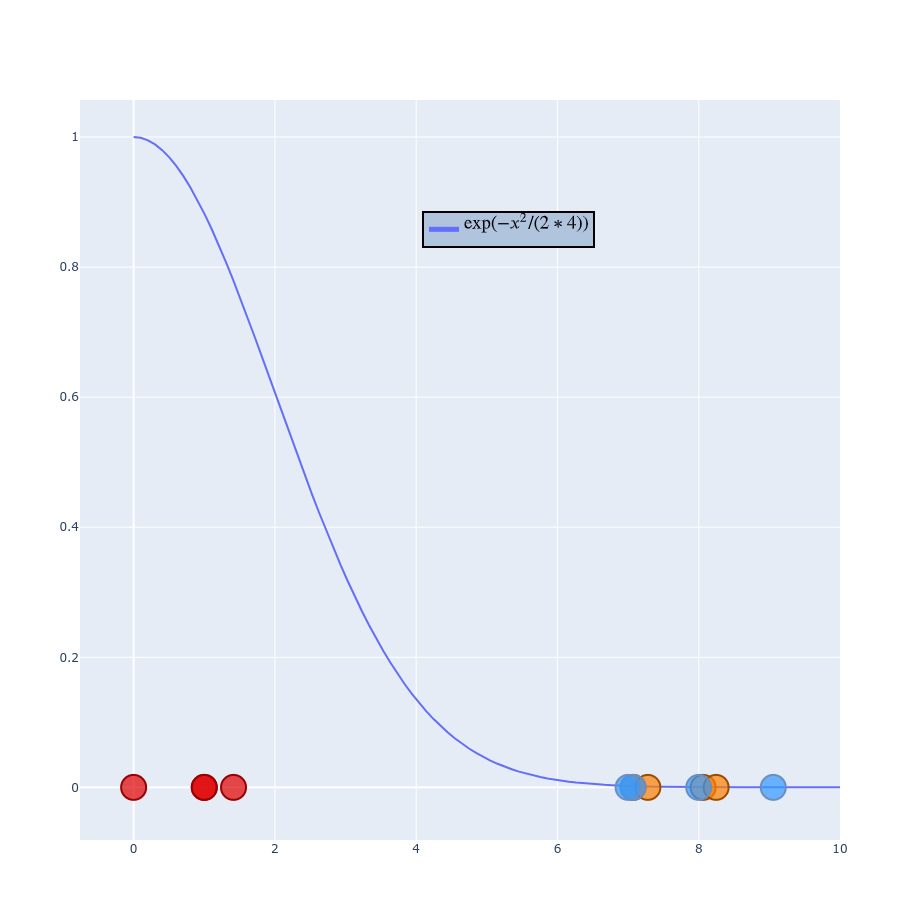
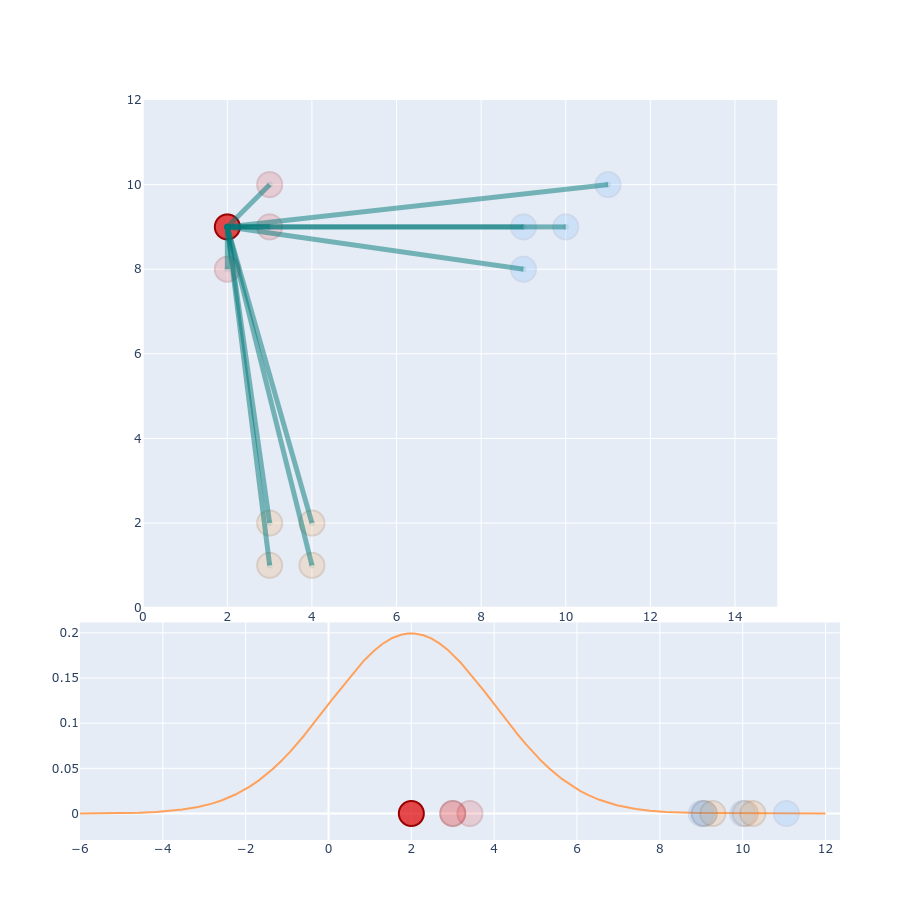
Part 2 - Low-dimensional space
$$ q_{ij} =\frac{\exp(-\left | y_i - y_j \right |^2 / 2\sigma_i^2)}{\sum_{k \neq l} \exp(- \left | y_k - y_l \right |^2 / 2\sigma_i^2)} $$ $$ q_{ij} =\frac{(1 + \left | y_i - y_j \right |^2 )^{-1}}{\sum_{k \neq l} (1 + \left | y_k - y_l \right |^2 )^{-1} } $$
Random Points
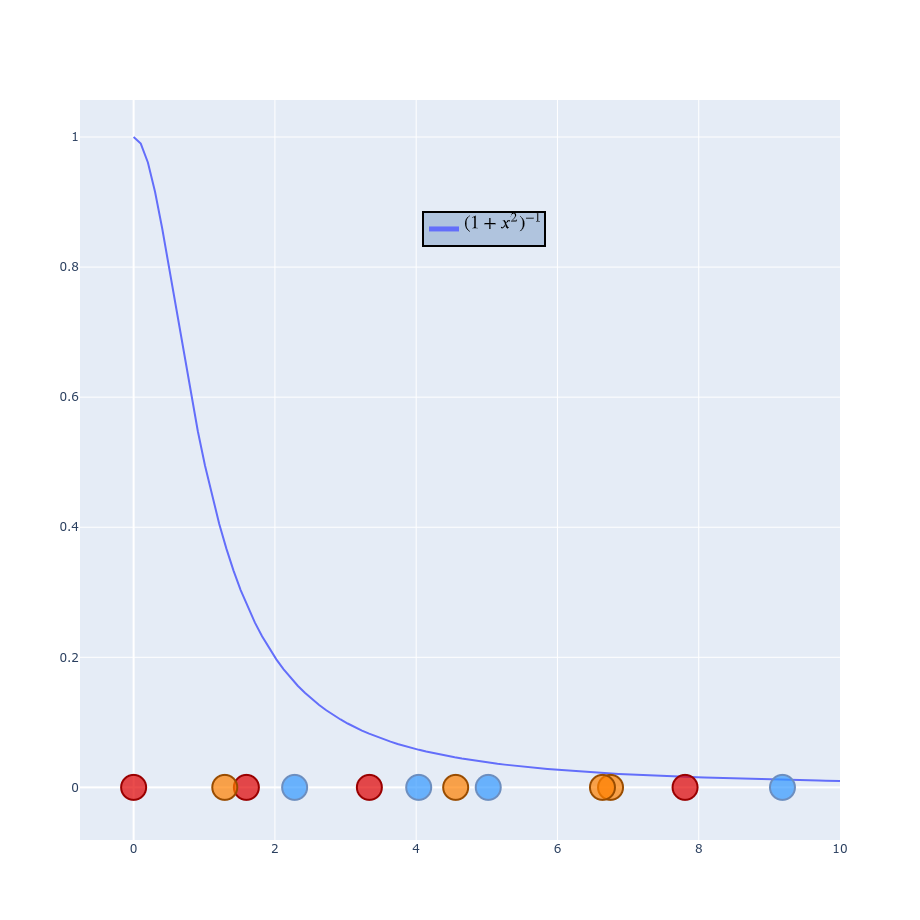
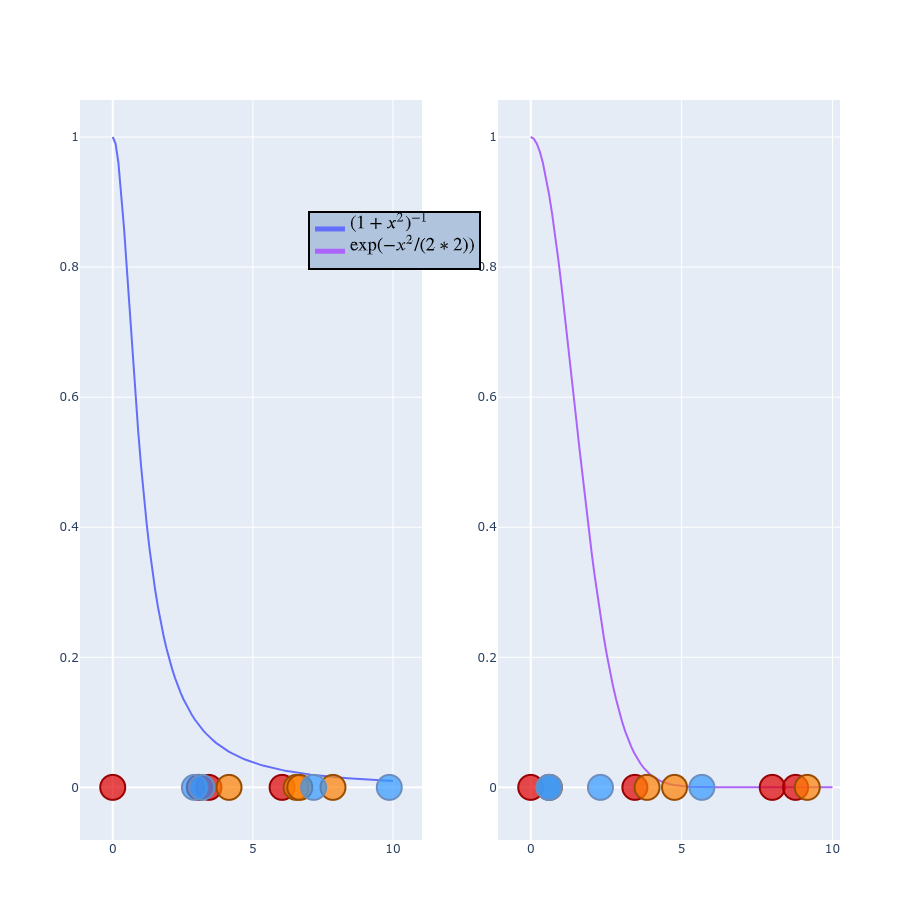
Final formulas
$$ p_{ij} = \frac{\exp(-\left | x_i - x_j \right |^2 / 2\sigma_i^2)}{\sum_{k \neq l} \exp(- \left | x_k - x_l \right |^2 / 2\sigma_i^2)} $$ $$ q_{ij} =\frac{(1 + \left | y_i - y_j \right |^2 )^{-1}}{\sum_{k \neq l} (1 + \left | y_k - y_l \right |^2 )^{-1} } $$
Gradient descent
Kullback-Leibler divergence $$ C = D_{\text{KL}}(P\parallel Q)=\sum _{x\in {\mathcal {X}}}P(x)\log \left({\frac {P(x)}{Q(x)}}\right) $$
Derivate $$ \frac{\delta C}{\delta y_i} = 4 \sum_j (p_{ij} - q_{ij})(y_i - y_j)(1 + \left | y_i - y_j \right | ^2)^{-1} $$
Gradient descent - iterations
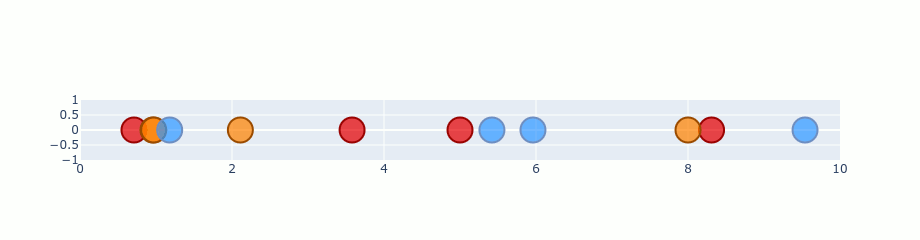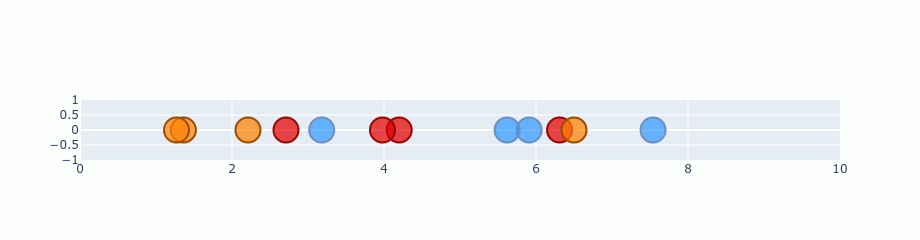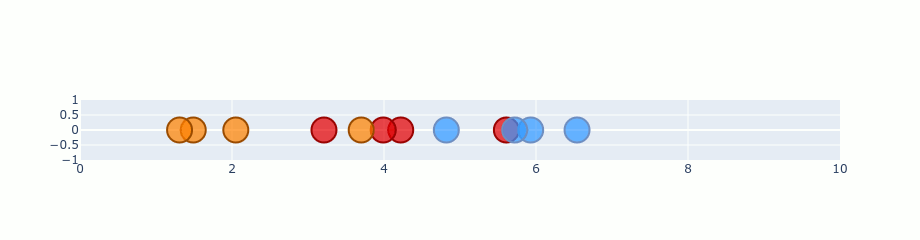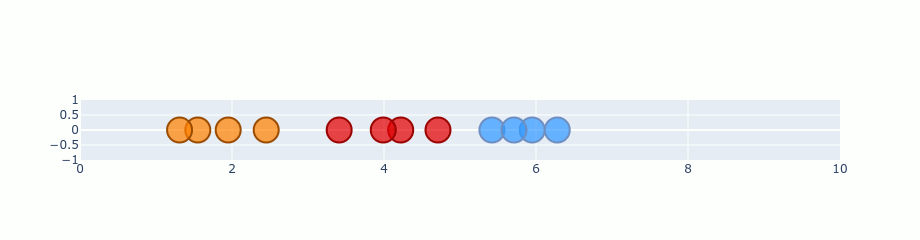
Optimizations
Early Compression Prevents clustering at the early stages with regularization.
Early Exaggeration Moves clusters by multiplying p values at the early stages.
Difficult data


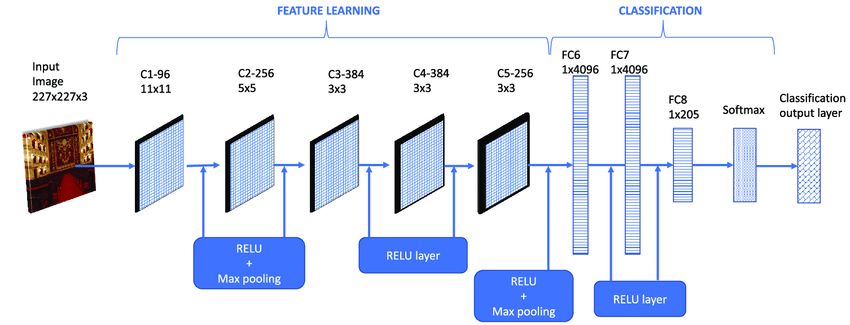
CNN applications
{kind=link}
What to remember?
- Great for linearly nonseparable data
- Iterative and non-deterministic
- Cannot be reused on different data
Thanks
"There's no such thing as a stupid question!"
Kemal Erdem | @burnpiro
https://erdem.pl
https://github.com/burnpiro